Optimisation de k-Nearest Neighbors (k-NN)
k-NN
GridSearchCV
Validation croisée
Optimisation
Python
Scikit-learn
Contexte
Ce projet, réalisé dans le cadre du BUT Science des Données (Université de Caen, 2025-2026), vise à optimiser l'algorithme k-Nearest Neighbors appliqué au dataset Breast Cancer Wisconsin. L’objectif principal est d’identifier la configuration de paramètres offrant la meilleure précision.
Objectifs du projet
- Comprendre les hyperparamètres de k-NN
- Analyser le compromis biais-variance
- Optimiser le modèle via GridSearchCV et RandomizedSearchCV
- Produire des visualisations (heatmaps, courbes)
Méthodologie
- Nettoyage et exploration du dataset
- Établissement d’un modèle baseline (95.6%)
- Étude de l’impact du paramètre k
- Recherche exhaustive via GridSearchCV
- Comparaison avec RandomizedSearchCV
- Évaluation finale sur données de test
Résultats
L’optimisation du modèle K‐NN a été réalisée à l’aide de la fonction GridSearchCV de la bibliothèque sklearn. Cette méth‐ ode permet de tester automatiquement plusieurs combinaisons d’hyperparamètres afin de trouver celle qui maximise la performance moyenne mesurée par validation croisée.
- Modèle de base : 95.6%
- Modèle optimisé : 98.2%
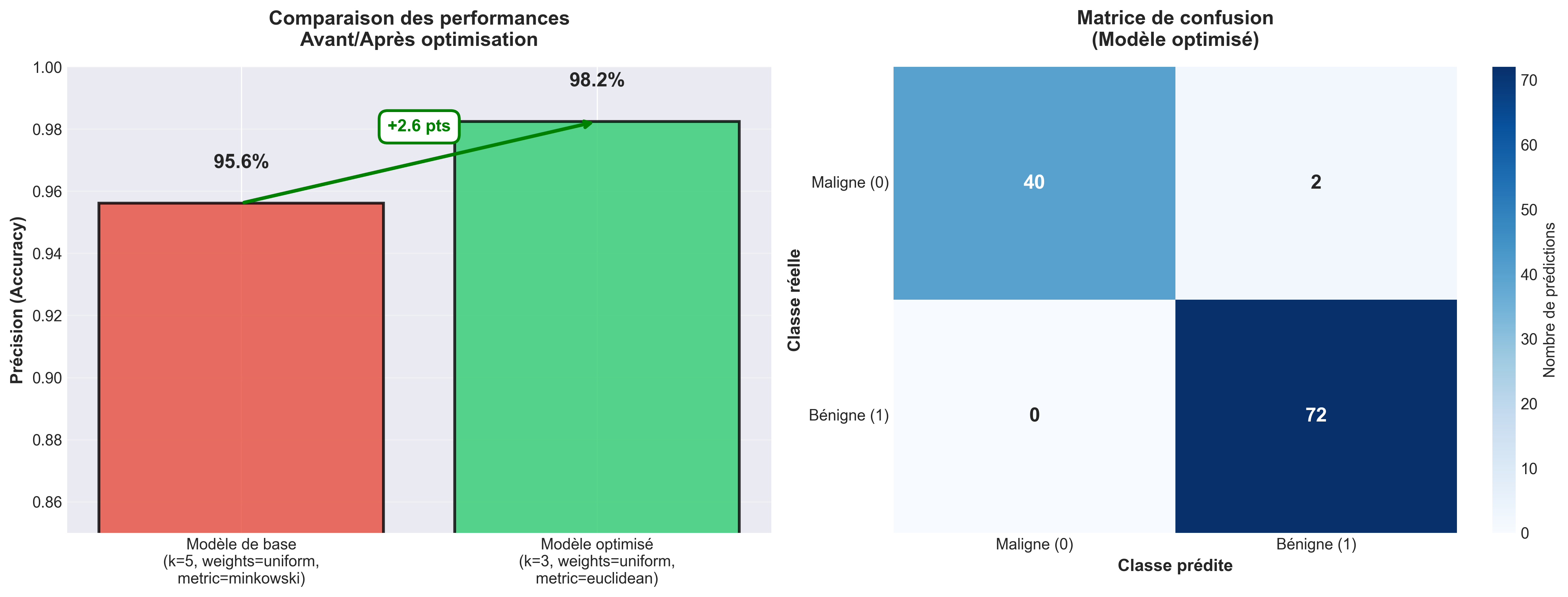
Visualisation extraite du poster — comparaison avant/après optimisation.
Technologies utilisées
- Python
- Scikit-learn
- NumPy, Pandas
- Matplotlib, Seaborn
- Jupyter Notebook
- Git & GitHub
- LaTeX (Poster scientifique)
- PowerPoint